Cortex for Enterprises
We leverage expert human data to evaluate, train, and continuously monitor AI agents so they perform reliably in real-world workflows.
.webp)
.webp)
.avif)
AI agents are only as intelligent as the data that shapes them.
To make reliable decisions, they need more than massive datasets—they need context, judgment, and domain expertise.
micro1 combines human expertise with advanced AI to evaluate and train agents that deliver real-world value.
.avif)
Challenges
.avif)
Unreliable Agent Behavior
Generic AI agents are not built for the complexity and uniqueness of enterprise environments which leads to a lack of consistency, controllability, and predictable behavior, resulting in hidden operational risk.

Evaluation Gaps
Agents are rarely tested against real procedures, edge cases, or compliance requirements and once deployed, they are left without ongoing evaluation.
.avif)
Trust and compliance remain a black box
Usage of AI systems are often opaque with unclear compliance risks, making it difficult to trust them and safely scale their use.
Our solution
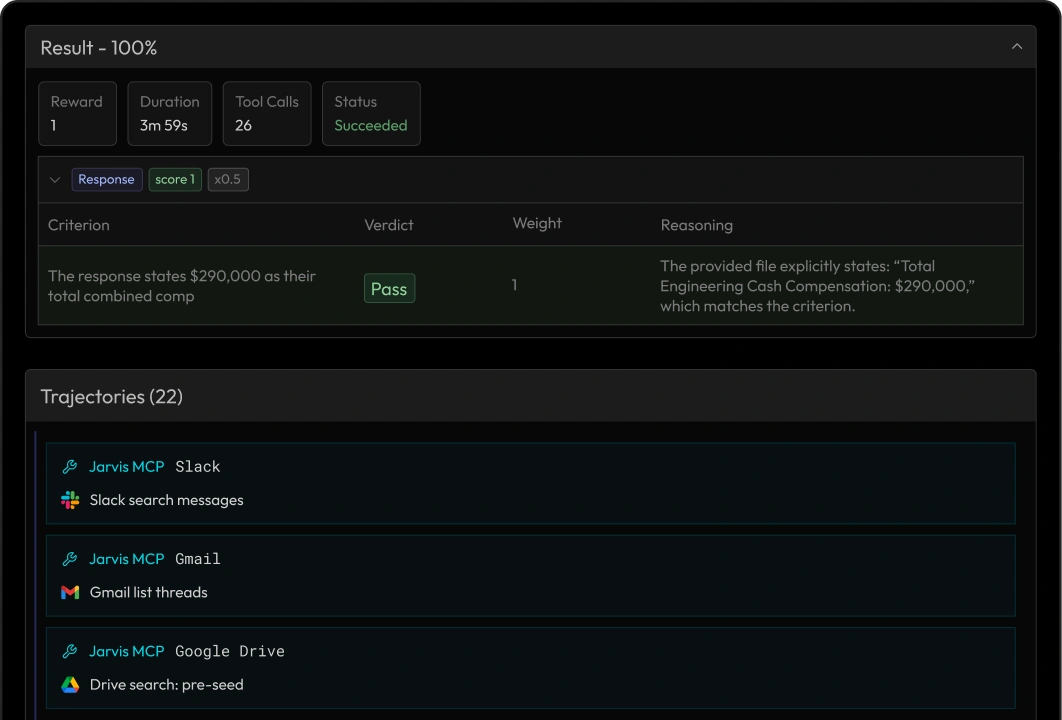
Contextual evaluations built on real workflows
We design evaluations that reflect how AI agents are actually used in production, grounded in real tasks, decisions, and success criteria instead of generic benchmarks.
Expert level human judgement
Domain experts evaluate agent outputs in realistic scenarios to surface reasoning gaps, edge-case failures, and risky behavior that automated tests do not catch.
.webp)
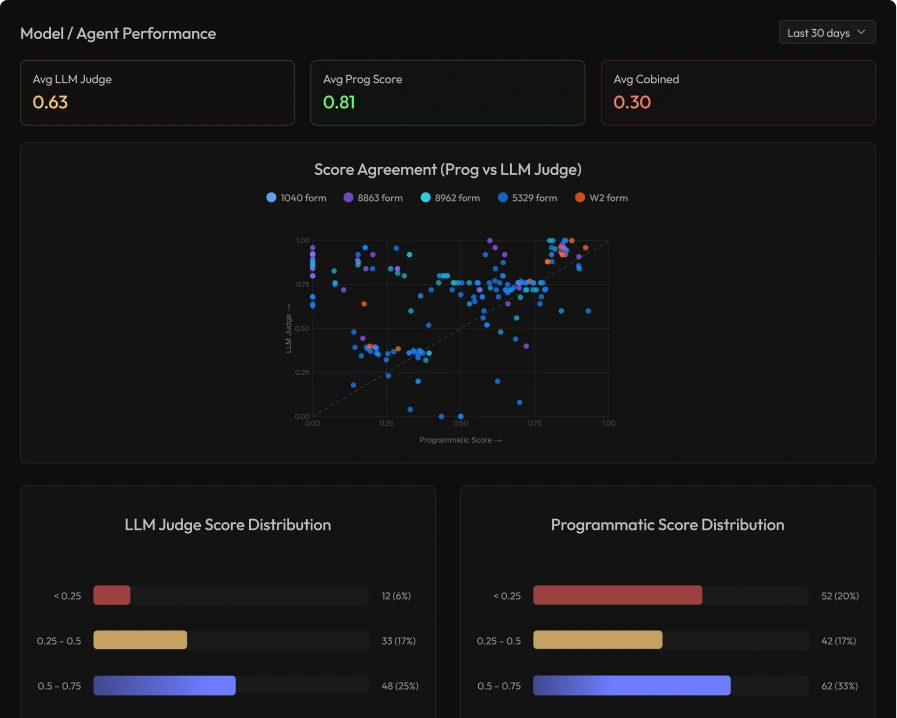
Data-driven improvement loops
Evaluation results feed directly into targeted data generation, fine-tuning, and ongoing monitoring so agent performance improves and stays reliable over time.
How it works
1
Evaluation design
Define realistic scenarios and success criteria based on real workflows
2
Expert-calibrated human judgment
Domain experts evaluate agent outputs against desired outcomes
3
Failure mode analysis
See where and why agents break down, including edge cases and high-risk decisions
4
Improvement pathways
Evaluation results translate directly into targeted data, fine-tuning, and workflow changes
5
Continuous evaluation
Agents are re-evaluated over time to maintain reliability, alignment, and performance
Impact

Faster Time to Production
Identify failure modes earlier, improve systems faster, and reduce costly iteration cycles.

Clear Visibility Into AI Performance
Understand where systems fail, why they fail, and what improvements will drive the greatest impact.

Greater Customer Trust
Improve consistency and accuracy in customer-facing and business-critical AI experiences.

Continuous Improvement Over Time
Improve consistency and accuracy in customer-facing and business-critical AI experiences.
